waymo 自动驾驶方案
not end to end, but mid 2 mid
ChauffeurNet
ChauffeurNet: Learning to Drive by Imitating the Best and Synthesizing the Worst
waymo resource: https://sites.google.com/view/waymo-learn-to-drive/
模仿学习 端到端的planning
Learning to Drive: Beyond Pure Imitation
abstract
- 模仿学习: imitation learning
- 数据增广: data augmentation
- 消融实验: ablation experiments and real world
introduction
data: 30 million real-world expert driving examples, corresponding to about 60 days of continual driving)
input
- not raw sensor input but mid-level representation
-
- top-down representation of the environment
-
- intended route
- as 2D boxes / road / traffic lifght states
- mid-level: easily tested and validated in closed-loop simulations
原始的模仿学习效果不好
改进: 通过数据增广,暴露出碰撞发生的bad event,再通过损失函数调教模型避免碰撞的发生 - loss augmentation: augment the imitation loss with losses that discourage bad behavior and encourage progress, - data augmentation: synthesize pertubations in the driving trajectory(comes from the mid-level input-output representation)
实验: - evaluate loss augmentation and data augmentation in simulation - drive a car in the real world
related work
- a resurgence for an end to end learning to drive
ch3 model architecture
3.1 top-down input representation
- a top-down coordinate system:
- $p_t=(x_t, y_t)$: location
- $\theta_t$: heading
- $s_t$: speed
- $W \times H$: image size
- $(u_0, v_0)$: ego location at image in pixel
- $\phi$: image resolution with meters/pixel
- $R_{forward}=(H-v_0)\phi$: fixed forward range
- input images:
- color: roadmap, lanes, stop signs, cross-walks, curbs etc
- grey: traffic lights,红黄绿的灰度不同
- single channel: speed limit
- route: target route
- agent box, current full bounding box
- dynamic objects
- past agent poses
- time elapsed information $\delta t$
- past $T_{scene}$: traffic lights and dynamic objects
- a potentially longer interval of $T_{pose}$: past agent poses
data augmentation: crop of the image from different heading
input representation: 1. 方便闭环验证 2. 方便使用模拟器中的数据(包括现实中无法获得的碰撞数据) 3. 2D,使用卷积
model formular: $p_0$ is known, and N iterations are performed and outputs a future trajectory $\left{\mathbf{p}{\delta t}, \mathbf{p}\right}$. Then this trajectory is fed to a control optimizer that computes detailed driving control(steering and braking commands).}, \ldots, \mathbf{p}_{N \delta t
相比与最底层的控制信号的输出(方向盘和油门),该方法输出的只是轨迹,再针对不同的车型参照该条轨迹优化出适合于当前车型的控制信号。Not the same as other programs which from sensors to controls.
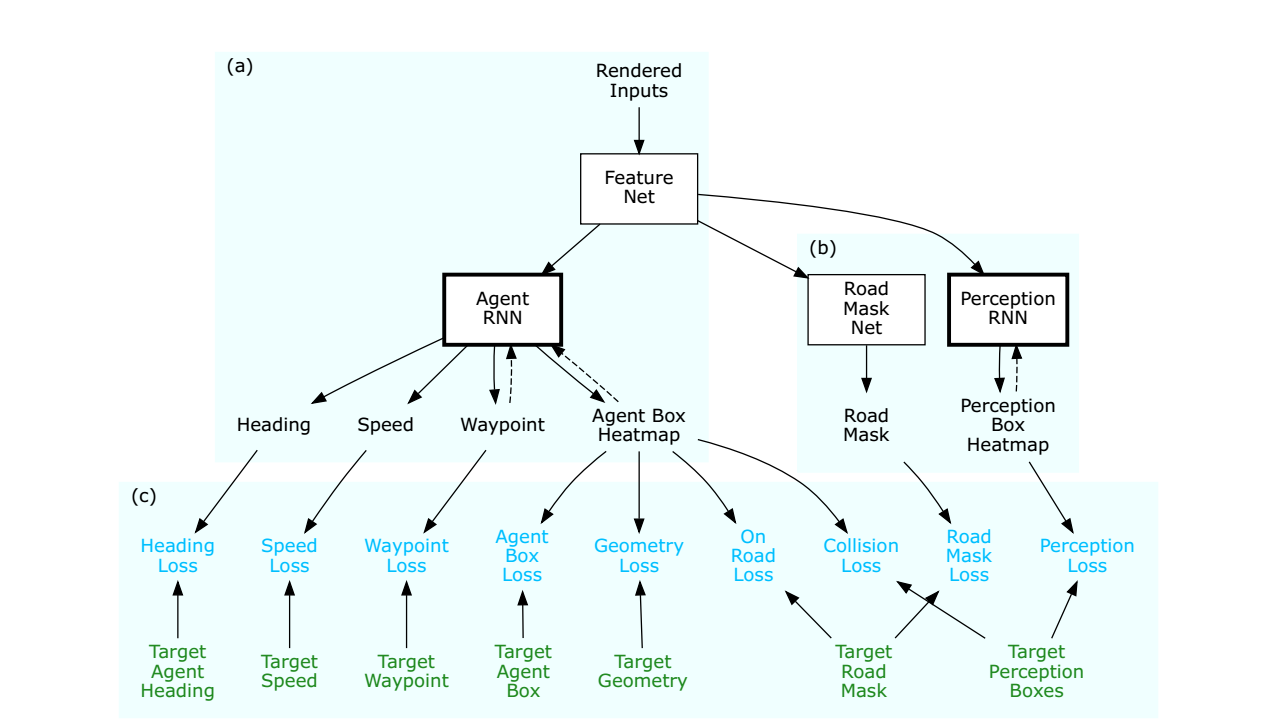
3.2 Model Design
- FeatureNet: convolutional feature network
- AgentRNN: iteratively predicts successive points
- trajectory: $t:p_x=(x_t, y_t), \theta_t, s_t$
- spatial heatmap for bounding box at each timestep
额外的网络训练增加feature提取的泛化性,类似优化中的约束。
- Road Mask Network: drivable areas of the field of view
- PerceptionRNN: iteratively predicts a spatial heatmap for any other moving agent
detail model
$M_k$: trajectory memory as the heatmap image, use arg-max operation to obtain the coarse pose prediction $p_k$ from this heatmap, than employ2 a shallow convolutional meta-prediction network with fully-connected layer that predicts a sub-pixel refinement of the pose $\delta p_k$ and the heading $\theta_k$ and speed $s_k$ - explicitly crafted memory model ??
3.2 System Architecture
imitating the expert
design loss
4.1 imitation losses
- probability distribution of the predicted pose: softmax
- heatmap of agent box: per-pixel sigmoid activation
- a regressed box heading output $\theta_k$
$L_1 $ loss for pose refinement and speed:
4.2 past motion dropout
防止网络只是简单地从历史轨迹中的某些迹象而不是从整个环境信息去推理动作,对历史轨迹进行50%的丢弃,之保留当前点,以强制网络从环境的整体信息去推理未来的轨迹。
beyond pure imitation
5.1 synthesizing perturbation adding realistic perturnations
- $\delta lat\in [-0.5, 0.5], \delta\theta \in [-\pi/3, \pi/3]$
- fit a smooth trajectory to the perturbed point
- filter by thresholding on maximum curvature
- allow collide, as negative example
- 1/10
5.2 beyond imitation loss
- collision loss
- measure overlap of predicted agent box
- add perturbation for later train
- on load loss
- measure overlap of the predicted agent
- geometry loss
- auxiliary loss
- co-training perceptionrnn loss:
- co-train road mask cross-entropy co-training: induce the feature network to learn better features that are suited to both tasks(另一个维度的投影)
5.2 imitation dropout
randomly dropping out the imitation losses
Experiments
data
- 80m x 80m
- $R_{forward} = 64m$
- data augmentation $\Delta = \pm 25^0$
models
closed loop evaluation
- model ablation tests
- nudging around a parked car
- Recovering from a trajectory perturbation
- Slowing down for a slow car
- input ablation test
- logged data simulated driving
- real world driving
open loop evaluation
failure modes
sampling speed profiles
Multipath
Multipath: Multiple Probabilistic Anchor Trajectory Hypotheses for Behavior Prediction
未来轨迹预测
VectorNet
encoding hd maps and agent dynamics from vectorized representation
Behavior prediction
TNT
Target-driven Trajectory Prediction
轨迹预测
Large Scale Interactive Motion Forecasting For Autonomous Driving : The Waymo Open Motion Dataset
Identifying Driver Interactions Via Conditional Behavior Prediction
Peeking Into The Future: Predicting Future Person Activities And Locations In Videos
STINet: Spatio-temporal-interactive Network For Pedestrian Detection And Trajectory Prediction
行人的end-to-end预测
ref
- blog
- paper