note6_model_based
YeeKal
•
•
"#"
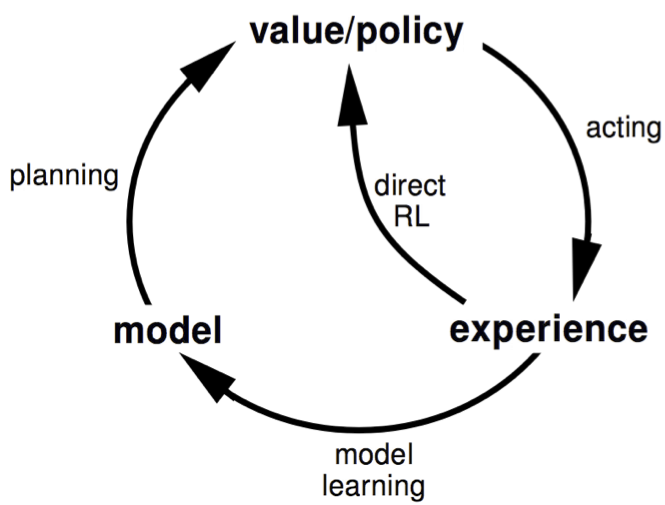
- learn a model from experience
- plan value function (and/or policy) from model
A model $M=
train process
select some complete episodes to train then this becomes a supervised learning problem.
- learning $s,a\rightarrow r$ is a regression problem
- learning $s,a\rightarrow s'$ is a density estimation problem
- update $\eta$ to minimise loss function
Dyna
Integrating learning and planning.
Dyna-Q algorithm:

Dyna2 algorithm:
