recsys
深度推荐系统中的损失函数
YeeKal
•
•
"#recsys"
sampled softmax loss: 通过采样部分负样本代替整体分母
Bayesian Personalized Ranking(BPR) loss
negative Sampling
- 只有一层Embedding层,即embedding可以通过label取出来,则直接在线选择
- 把负样本的label作为输入
- 把batch中其他样本作为负样本
triplet less
- 目标是拉近与正样本的距离,拉远与负样本的距离
-
easy triplets: 正样本距离本来就很近,不需要优化,或者说优化的意义不大
-
hard triplets: $d(q,d_+) > d(q,d_-)$, 正样本的距离比负样本还要远
-
semi-hard triplet: 距离适中
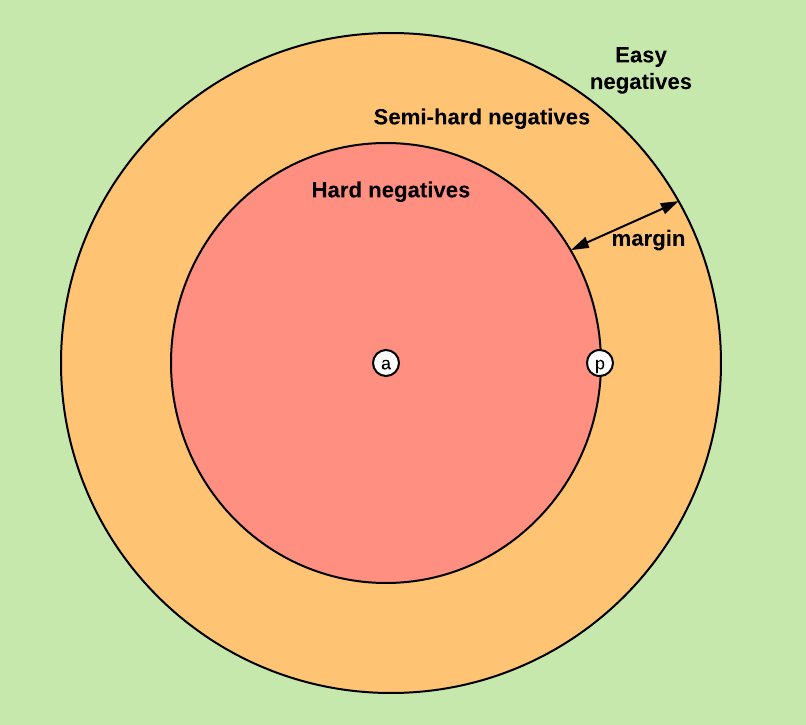
在人脸识别领域,anchor和负样本是同一种事物,都是人脸;而在搜索推荐领域,anchor一般为用户,政府样本为物品。这样在构造数据集的方法上略有不同。
实现的多种方式:
- online: 在同一个batch中在线计算选择正负样本
- offline: 手动选择正负样本
- batch all: select all the valid triplets, and average the loss on the hard and semi-hard triplets.
- crucial point here is to not take into account the easy triplets (those with loss 0 ), as averaging on them would make the overall loss very small $\circ$
- this produces a total of $P K(K-1)(P K-K)$ triplets $(P K$ anchors, $K-1$ possible positives per anchor, $P K-K$ possible negatives)
- batch hard: for each anchor, select the hardest positive (biggest distance $d(a, p))$ and the hardest negative among the batch
- this produces $P K$ triplets
- the selected triplets are the hardest among the batch
- batch all: select all the valid triplets, and average the loss on the hard and semi-hard triplets.
实现
offline:
anchor_output = ... # shape [None, 128]
positive_output = ... # shape [None, 128]
negative_output = ... # shape [None, 128]
d_pos = tf.reduce_sum(tf.square(anchor_output - positive_output), 1)
d_neg = tf.reduce_sum(tf.square(anchor_output - negative_output), 1)
loss = tf.maximum(0.0, margin + d_pos - d_neg)
loss = tf.reduce_mean(loss)
online:
- Triplet loss in TensorFlow
- [tensorflow semihard]