recsys
推荐系统中的向量检索03-图嵌入
YeeKal
•
•
"#recsys"
- line(Lareg-scale information network embedding MSRA 2015)
- eges(Enhanced Graph Embedding with Side Information): 2018 Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
- SDNE (Structural deep network embedding)
- graphsage(2017)
graph embedding VS sequence embedding
index
- graph pooling
- GAE(graph auto encoder)
- [2018 KDD PinSAGE]
- [2017 NIPS GraphSAGE]
- 2016 KDD node2vec
- [2014-deep walk]
2018 KDD PinSAGE
2017 NIPS GraphSAGE
transductive learning vs inductive learning
- transductive learning: 直推学习,只能对出现的节点生成表示向量
- inductive learning: 归纳学习,能通过连接馆学学习未见过节点的表示信息
graphsage method
根据连接关系生成当前节点的表示信息。
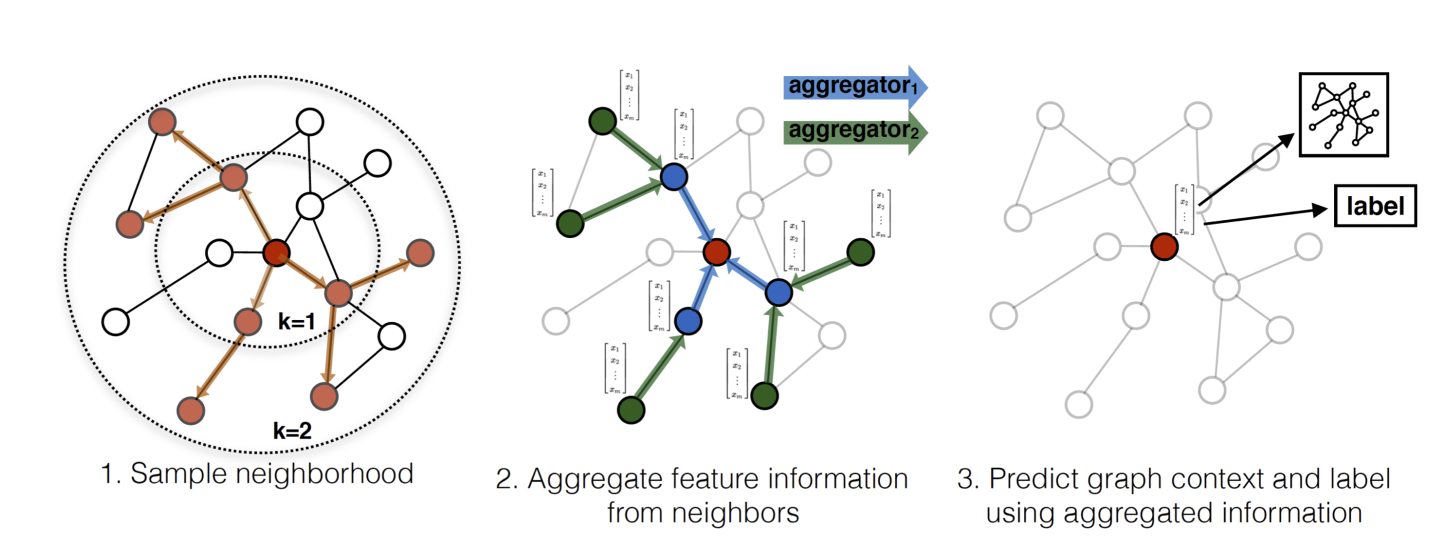

- Weisfeiler-Lehman Isomorphism Test: The GraphSAGE algorithm is conceptually inspired by a classic algorithm for testing graph isomorphism
-
aggregator architecture
- mean aggregator:
- LSTM aggregator
- pooling aggregator:
2016 KDD node2vec
优化目标:最大化当前节点的隐向量预测周围节点的概率
根据条件独立假设(Conditional independence): 在给定当前节点下,临近点的概率与其余顶点无关
特征空间对称假设(Symmetry in feature space): 一个节点作为源节点与作为邻近节点时的隐向量是一致的
最终优化目标转化为:
其中$Z_{u}=\sum_{v \in V} \exp (f(u) \cdot f(v))$, 但在实际应用中采用负采样以降低$Z_{u}$的计算复杂度。
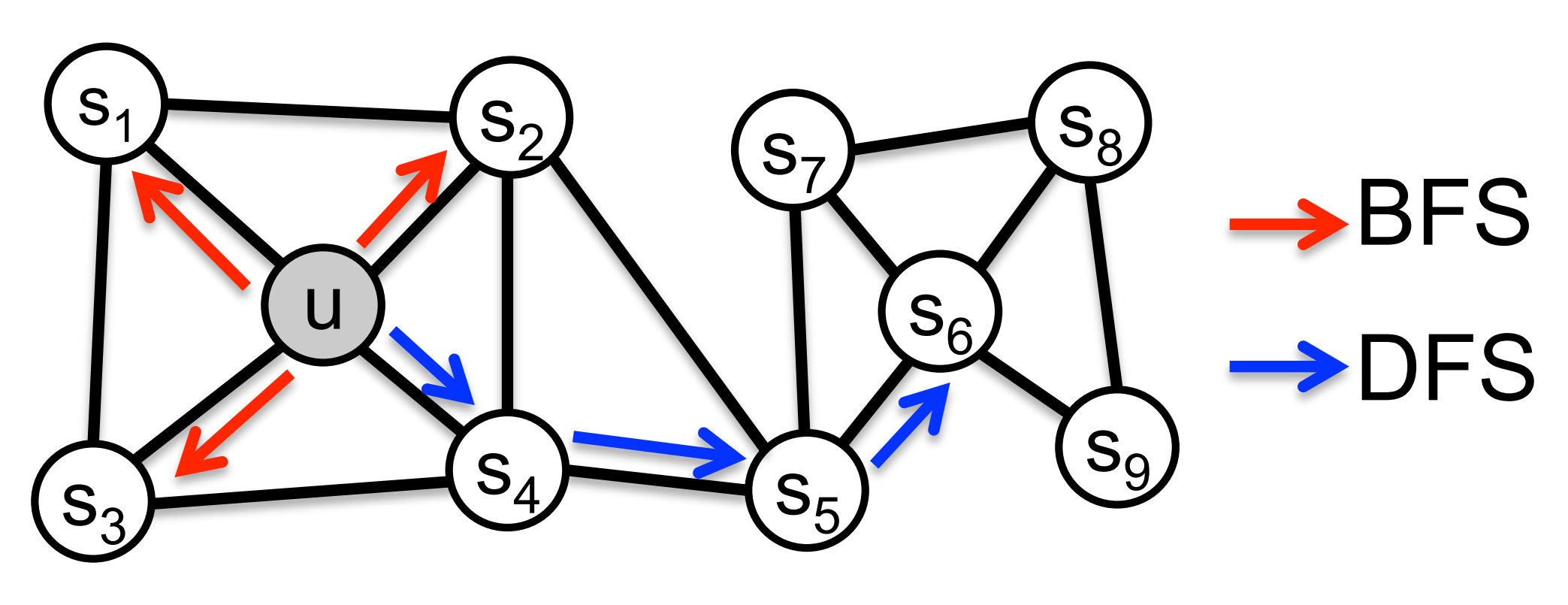
经典搜索策略
- BFS: 广度优先搜索
- homophilic equivalence(同质等价): 相连接的节点在隐向量空间更为接近
- DFS: 深度优先搜索
- structural equivalence(结构等价):
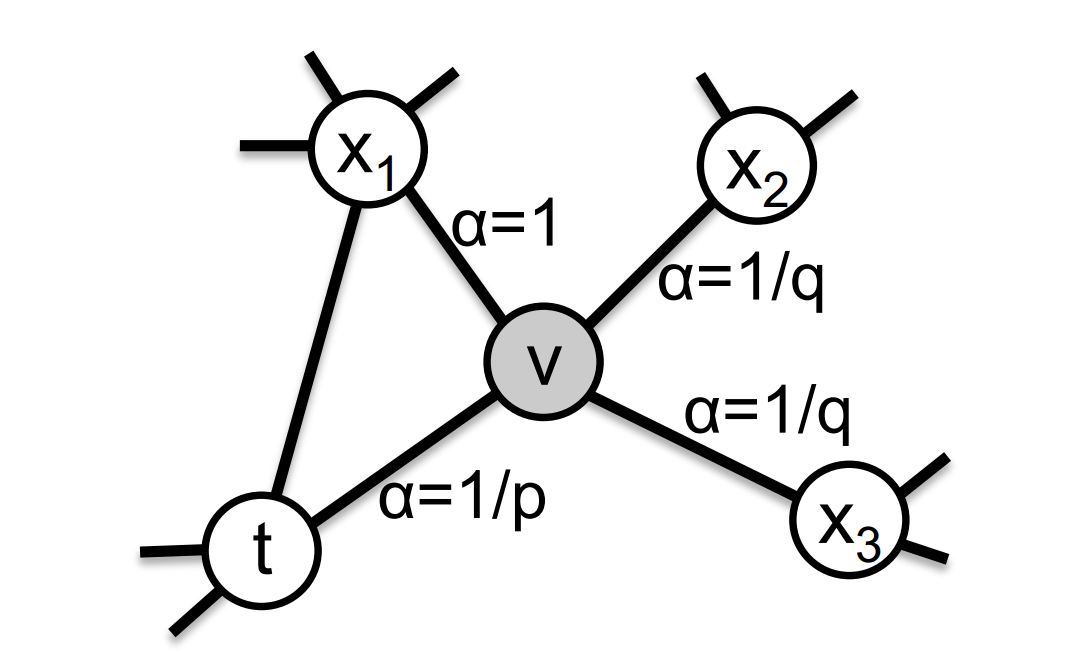
有偏随机游走(biased random walk)
针对当前节点$v$访问下一节点$x$的概率为:
其中:
$$$$ - $d_{tx}$: - 0代表下一个节点为$t$,即当前节点的上一个节点,即还原 - 1代表该点与$t,v$相距皆为1,即$v,x$都环绕在节点$t$周围,类似BFS搜索 - 2代表远离节点$t$,即类似DFS搜索 - return parameter, p: 表示下一个节点与上一个节点相同的概率 - in-out parameter, q: 控制游走向外还是向内。 若$q>1$, 则倾向于访问与上一个节点更近的节点,偏向BFS;反之则偏向DFS。
2015 LINE
2014 Deep Walk
random walks:
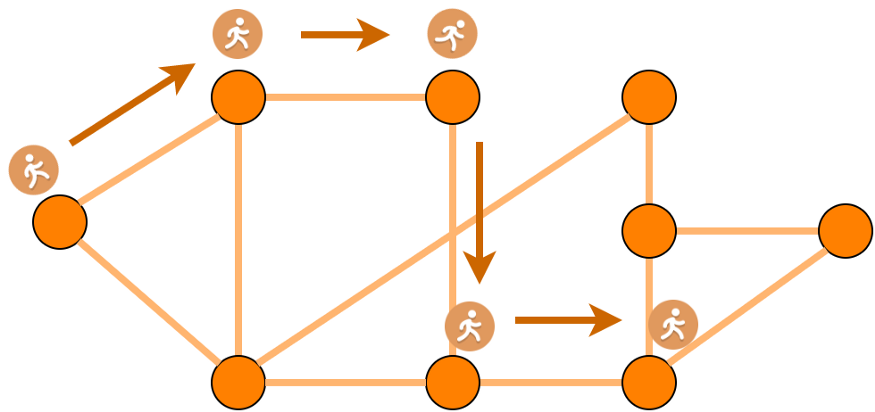
two stages:
- random walk generator
- 通过随机游走产生$k$个长度为$l$的节点序列作为候选节点集合
- 根据假设"Adjacent nodes are similar and should have similar embeddings",每一个节点序列应该有相近的向量表达
- 方便并行化
- skipgram algorithm
- 对于给定的语料,skipgram假设在一定大小窗口内的词应该有更相近的向量表达,这一窗口也叫做上下文
- 对应到deepwalk,在第一步生成的节点序列可以认为是一个上下文窗口,因此可以用同样的方法来训练,即用当前节点预测上下文窗口内的节点
- optimization
- Hierarchical Softmax
- Parallelizability with asynchronous version of stochastic gradient descent (ASGD)
- variants
- srtreaming
- non-random walks
ref
- blog
- personal code
- paper
- project