recsys
推荐系统中的向量检索00-概述
YeeKal
•
•
"#recsys"
匹配和检索
- semantic matching: 语义匹配/文本匹配
- embedding-based retrieval: 语义检索/语义召回/向量召回/向量检索/
匹配和检索并没有统一的叫法,或者两者是有很大交叉的领域。匹配更多的应用在文本上面,而检索则是指搜索推荐中的应用。搜索中一般称为query和doc的匹配/检索,而推荐中称为user和item的匹配/检索,或者广告领域中的query-ad/user-ad。其实通过一个query召回doc,也可以说成是给定一个query匹配最相近的doc。本笔记专注于针对搜索推荐场景的向量检索,或者以下我们统称匹配/检索为向量检索。
- [语义/向量][检索/索引/匹配]一般指两大类应用:
- 应用于文本:这类方法更加丰富多样,并且应用于多种nlp场景,比如问答/机器翻译/段落匹配等。参考MatchZoo-py
- 应用于各种实体的:工业应用场景较多,比如电商(淘宝,京东,amazon),社交(facebook)等。可以说在有推荐/搜索的地方都可以应用。
- 检索对象/术语:
- doc/query, user/item
向量检索的三大方法
- 双塔模型(two tower model): 又称为representation learning。doc和query分别训练,由于模型分离,便于在doc端建索引,使用ann方法召回。
- 单塔模型:interaction learning.doc和query有特征交互,复杂度增大。 如阿里的tdm
- 图模型(graph embedding):图神经网络学习,最后用ann召回
双塔模型
dssm开山之作。之后为了捕捉时序信息,有通过CNN进行的改进和通过rnn进行的改进。
- Based on DNN
- DSSM: Learning Deep Structured Semantic Models for Web Search using Click-through Data (Huang et al., CIKM '13)
- Based on CNN
- CDSSM: A latent semantic model with convolutional-pooling structure for information retrieval (Shen et al. CIKM '14)
- ARC I: Convolutional Neural Network Architectures for Matching Natural Language Sentences (Hu et al., NIPS '14)
- CNTN: Convolutional Neural Tensor Network Architecture for Community-Based Question Answering (Qiu and Huang, IJCAI'15)
- Based on RNN
- LSTM-RNN: Deep Sentence Embedding Using the Long Short Term Memory Network: Analysis and Application to Information Retrieval (Palangi et al., TASLP '16)
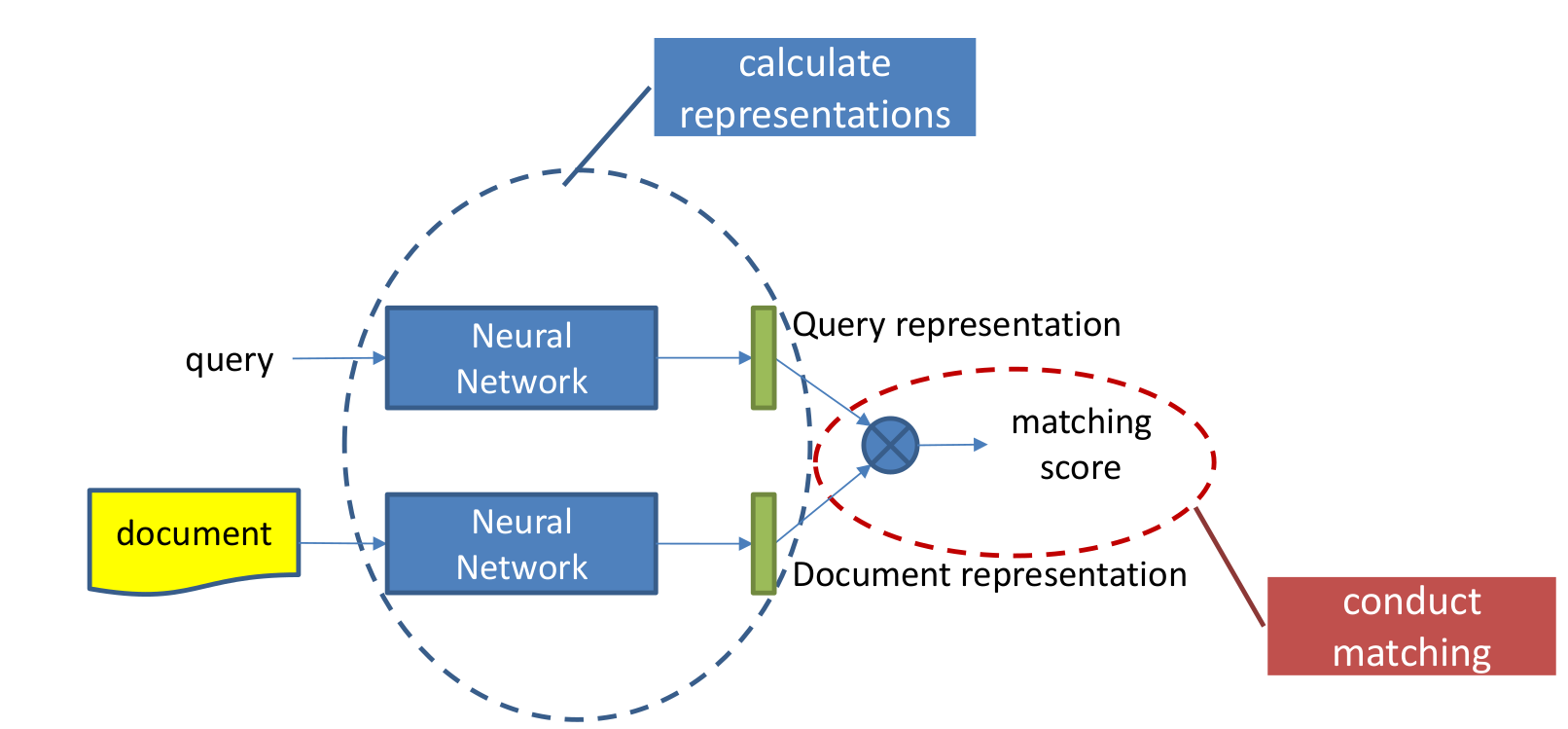
相似度函数/匹配函数计算:
- cosine similarity:
- dot product
- multi-layer perception (ARC-I)
- neural tensor networkd(CNTN)
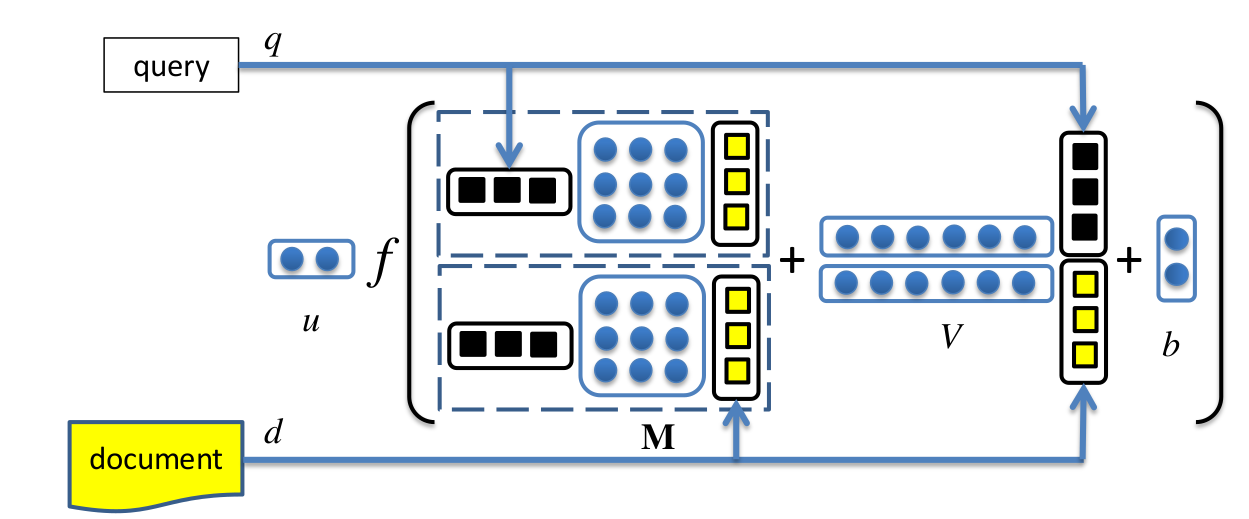
单塔模型
- Matching with word-level similarity matrix
- ARC II (Hu et al., NIPS '14)
- MatchPyramid (Pang et al., AAAl '16)
- Match-SRNN (Wan et al., IICAI '16)
- Matching with attention model
- Decomposable Attention Model for Matching (Parikh et al., EMNLP '16)
- Combining matching function learning and representation learning
- Representation Learning + Matching Function Learning Duet (Mitra et al., WWW'17)
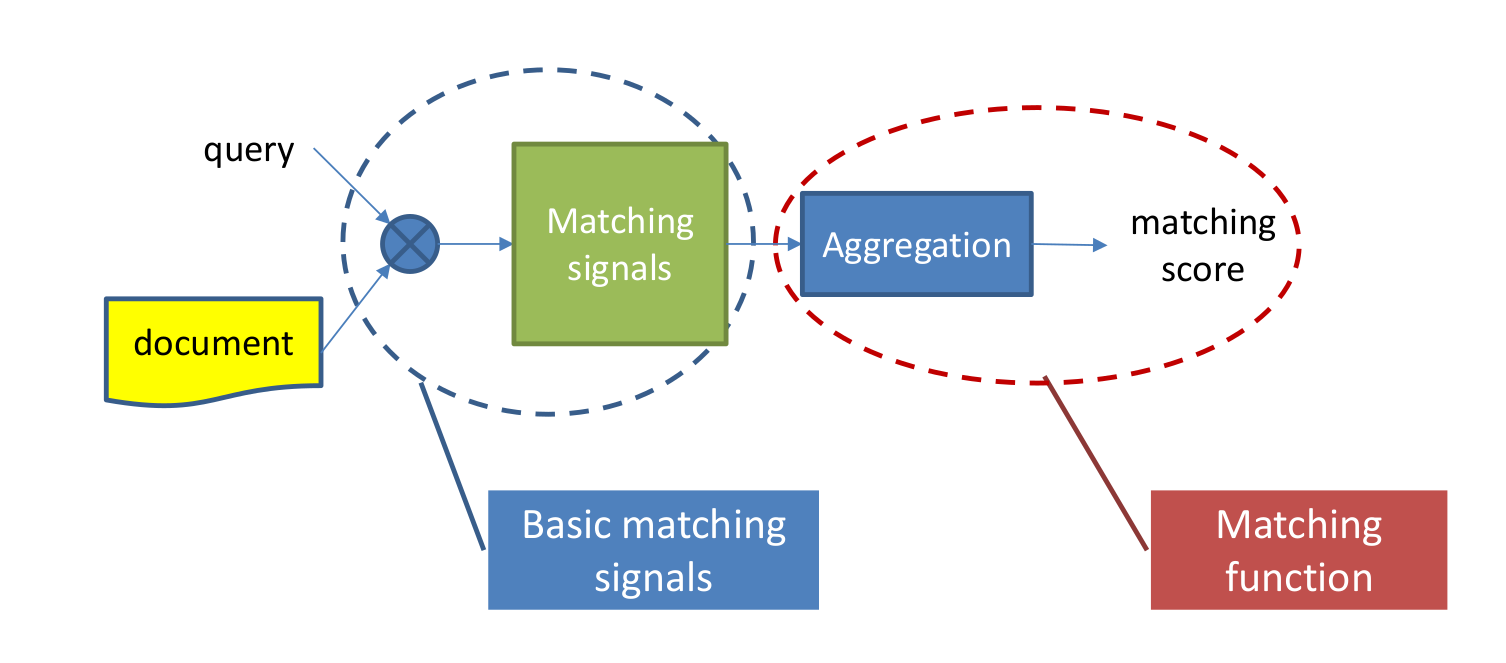
图模型
- random walk
- deepwalk(2014)
- node2vec(2016)
- eges(2018)
- line(Lareg-scale information network embedding MSRA 2015)
- SDNE (Structural deep network embedding)
- graphsage(2017)
关于匹配
文本的匹配
Typical Query-Document Relevance Matching Methods:
- Based on global distribution of matching strengths
- DRMM (Guo et al., CIKM '16)
- aNMM (Yang et al., CIKM '16)
- K-NRM (Xiong et al., SIGIR '17)
- Conv-KNRM (Dai et al., WSDM '18)
- Based on local context of matched terms
- DeepRank (Pang et al., CIKM '17)
- PACRR (Hui et al., EMNLP'17)
推荐系统中的匹配:
- Collaborative Filtering: Models are built based on user-item interaction matrix only.
- DeepMF: Deep Matrix Factorization (Xue et al, IJCAI'17)
- AutoRec: Autoencoders Meeting CF (Sedhain et al, WWW'15)
- CDAE: Collaborative Denoising Autoencoder (Wu et al, WSDM'16)
- Collaborative Filtering + Side Info: Models are built based on user-item interaction + side info.
- DCF: Deep Collaborative Filtering via Marginalized DAE (Li et al, CIKM'15)
- DUIF: Deep User-Image Feature (Geng et al, ICCV'15)
- ACF: Attentive Collaborative Filtering (Chen et al, SIGIR'17)
- CKB: Collaborative Knowledge Base Embeddings (Zhang et al, KDD'16)
特征处理
- labelEncoding: 离散特征编程数字
- OneHotEncoding
- HashEncoding
- hash trick
- hash 冲突
- embedding
- 多值离散特征: 相加,平均
- 多个特征: 拼接