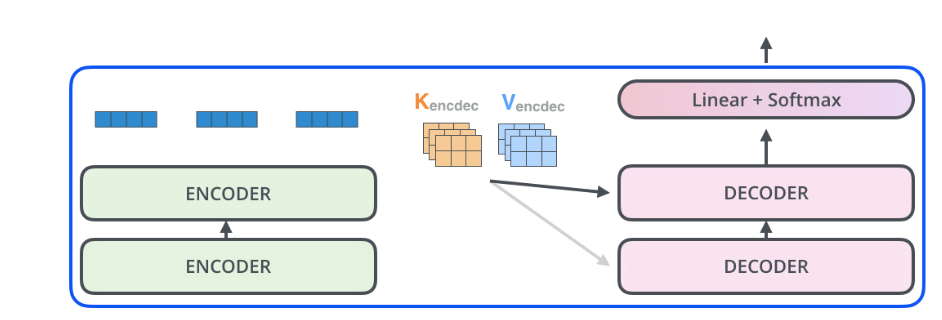
10 transformer
attention
Encoder-Decoder框架没有体现出注意力集中,即Decoder使用的编码后的隐藏语义是同一个,没有体现出对于不同词的不同的关注度(权重)。而注意力集中则是对于不同的词给予不同的权重。
Attention中常用的三个概念:Q(query),K(key),V(value). query是一个向量,K是一个包含多个$k_i$的矩阵,V也是一个包含多个$v_i$的矩阵。事实上每一个${k_i,v_i}$组成一个$k-v$对,而把所有的$k-v$对又称为Source。attention值则是通过某一运算关系$f$得出query和${k_i}$每一个向量的相似性,又被称为权重;再根据权重对每一个向量${v_i}$求和得到。而这些不同的权重就是注意力集中的体现。计算框架如下: $Similarity$函数有不同的计算方式: - 点乘:$s(q, k)=q^{T} k$ - cos相似度:$s(q, k)=\frac{q^{T} k}{|q| \cdot|k|}$ - 多层感知机: $s(q, k)=v_{a}^{T} \tanh (W q+U k)$ - 串联方式:
Attention有多种分类方式: - 计算区域: - soft attention: 对每一个key都有一个权重 - hard attention: 只取权重最大的key - local attention: 取一定窗口内的key - 所用信息: - general attention - local attention - 结构层次: - 单层attention - 多层attention - Multi-head attention: 有多个不同的query,$Q={q_i}$. 每个query都有对应的权重,相当于不同的query关注source中不同的部分,最后再把结果拼接起来:
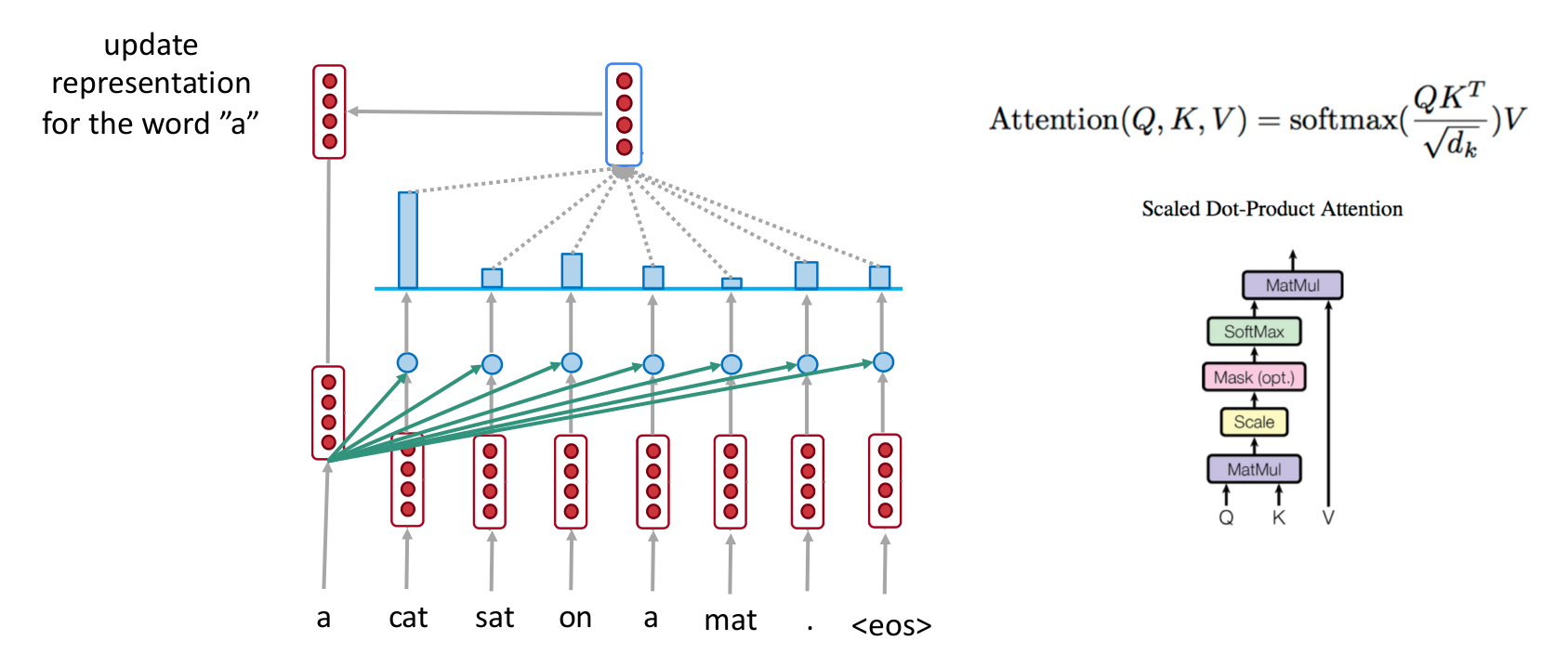
下式是Transformer用到的计算方式,又被称为Scaled Dot-Product Atention. 相似度计算类似点积,其中分母是为了避免相似度过大。
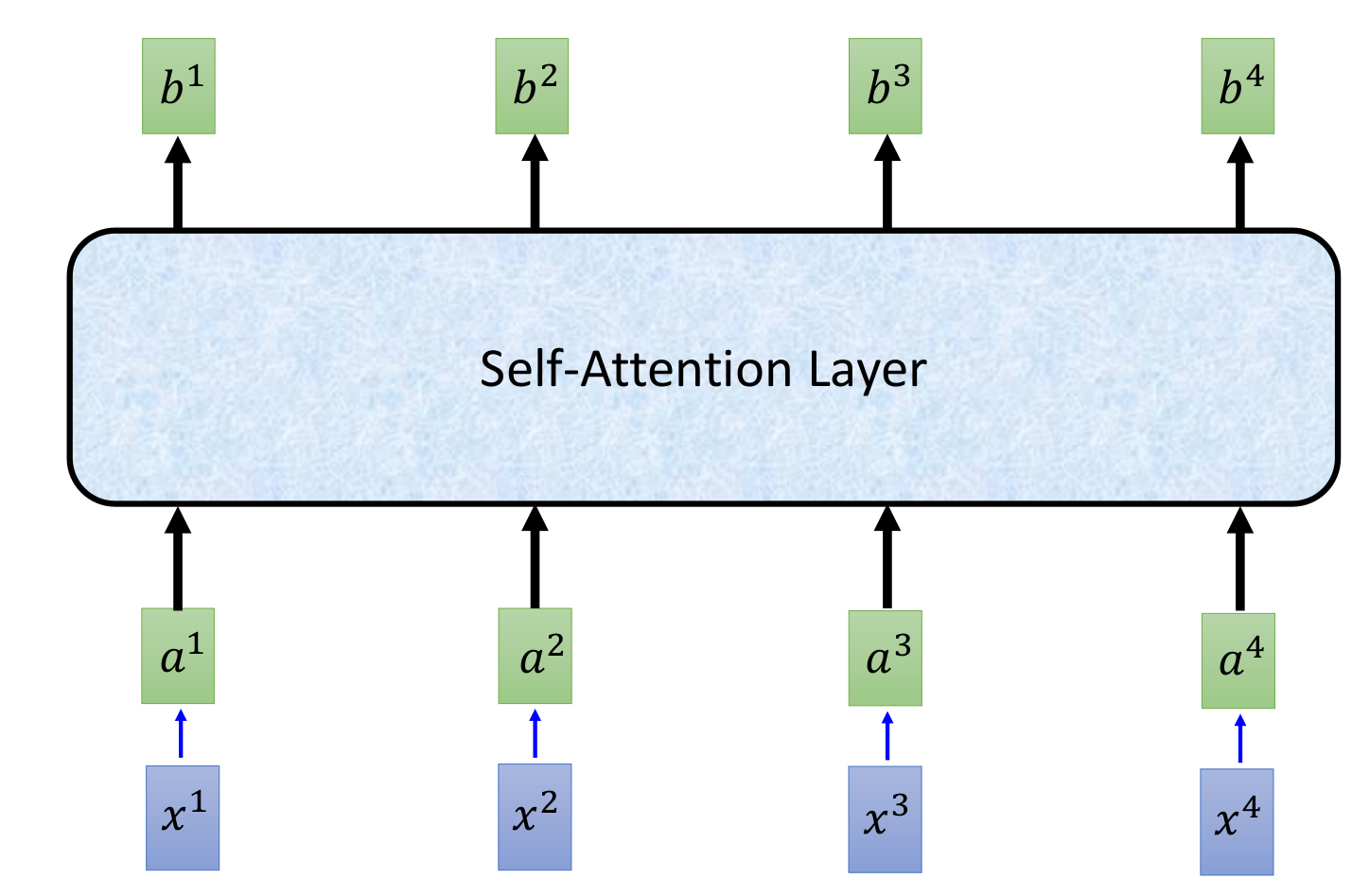
self attention
把文本中的每个词最为query,其他词作为source更新当前文本的表示方式。
Multi-Head Attention
Trandformer
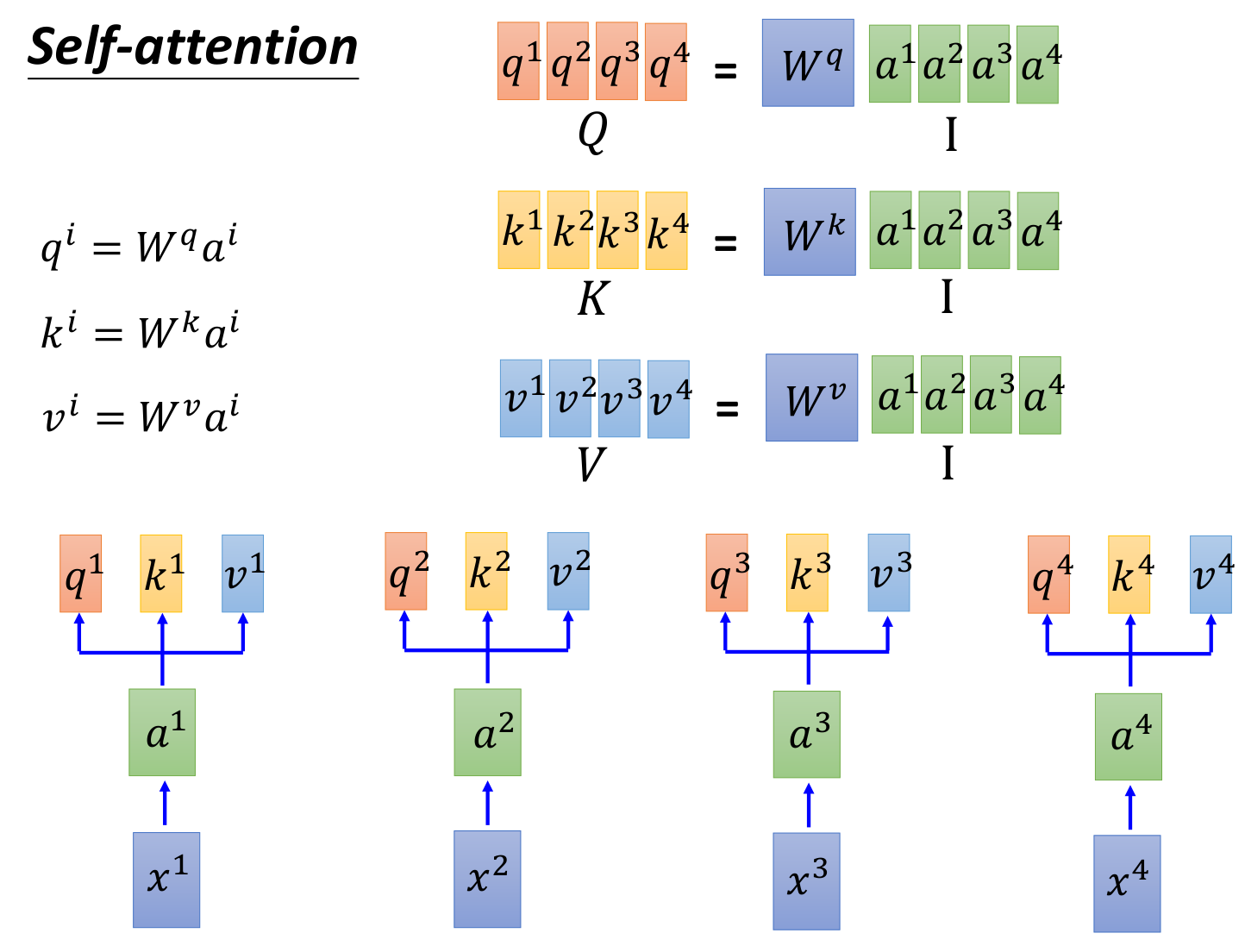
self attention in transformaer
a1. 针对词向量构造Q,K,V. $W^q,W^k,W^v$为共享参数
a2. 生成权重系数(这里相似度计算省略了归一化分母,论文中分母取词向量维数的开方)
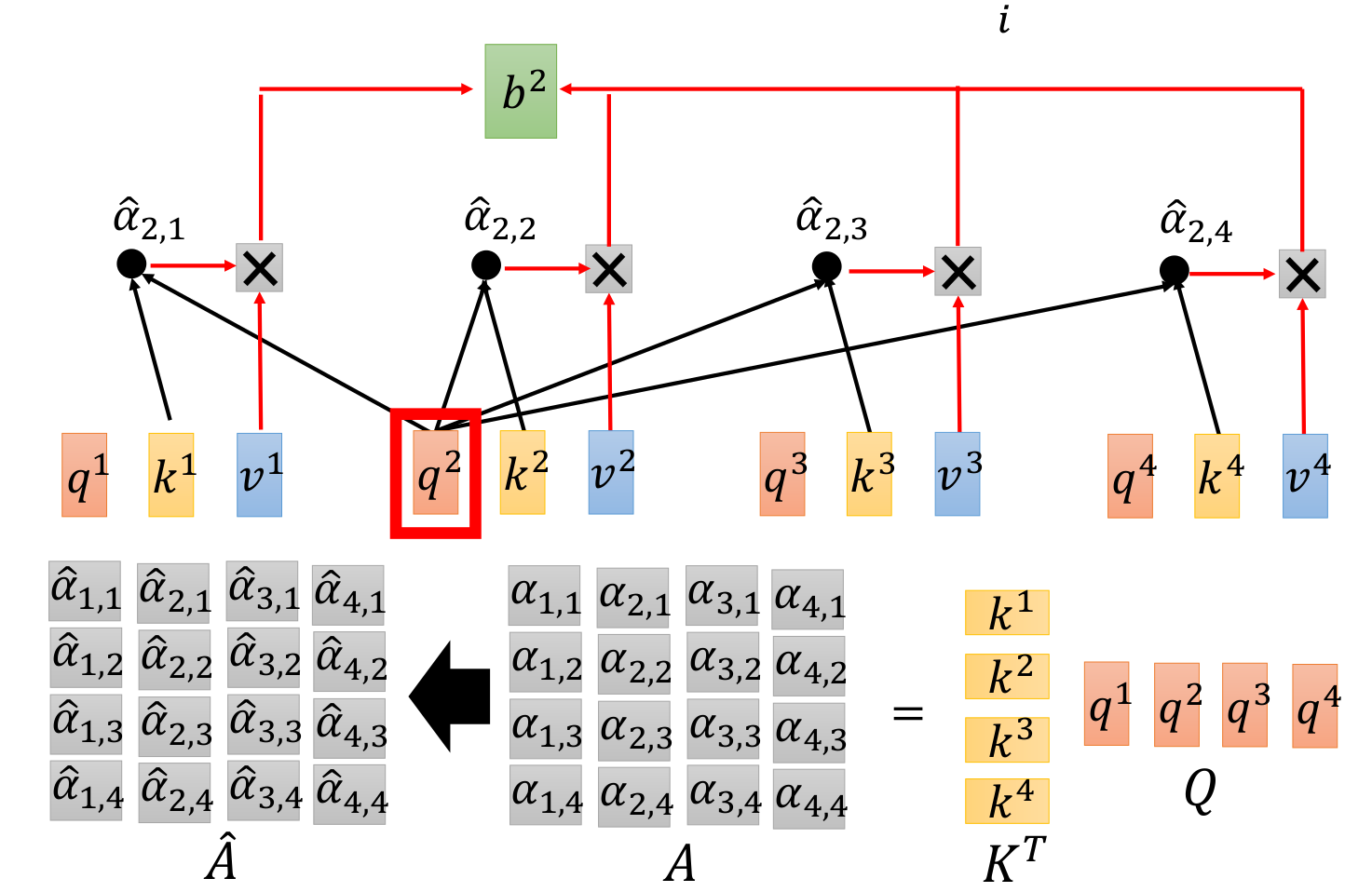
a3. 权重加权求和
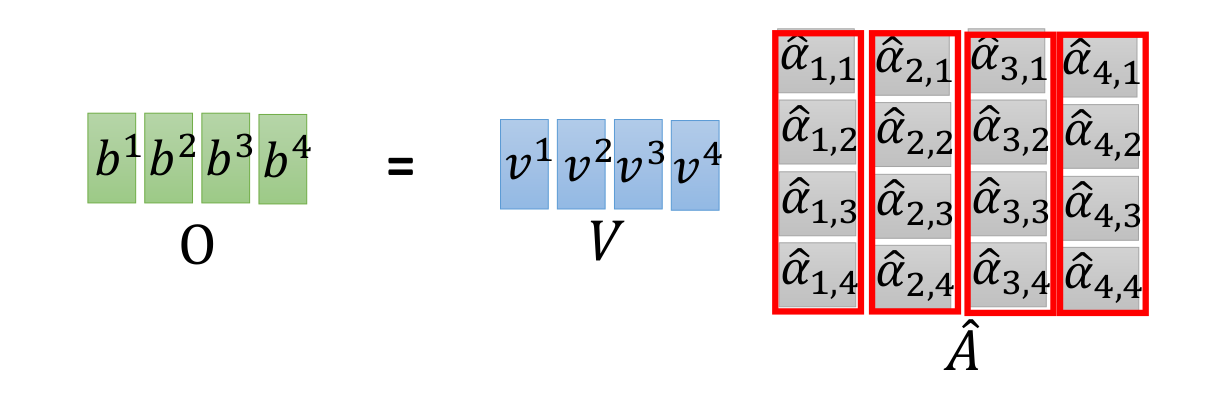
a4. 总结 (矩阵并行运算,方便在gpu加速)
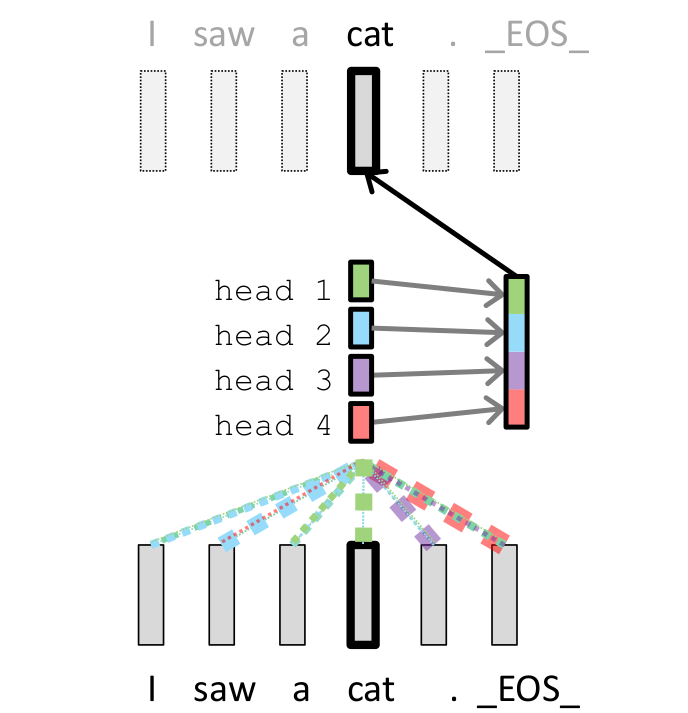
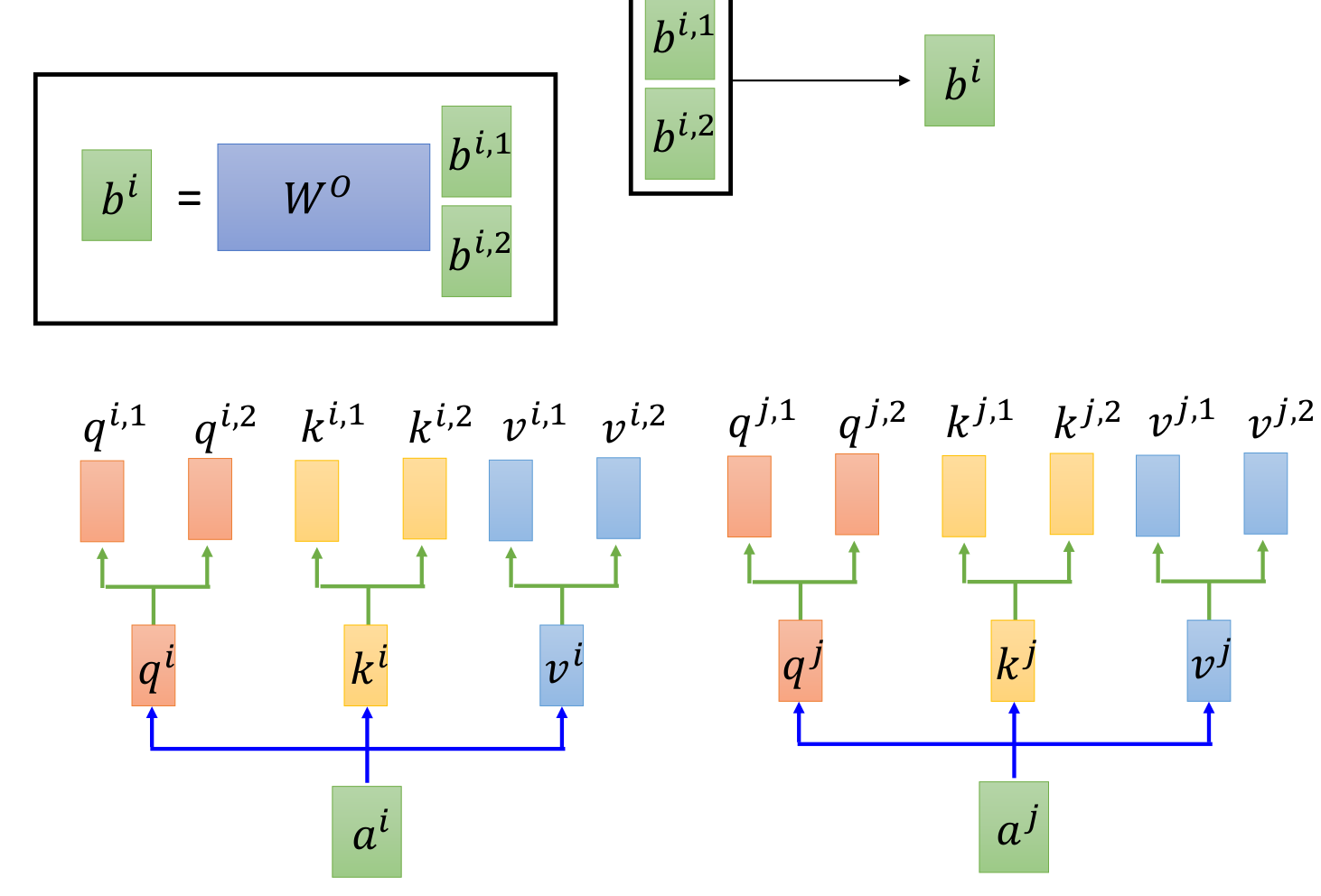
Multi-Head Attention
a1. 每个词生成多个{q,k,v},论文中有8个head
position encoding
位置编码加入了词的位置信息,形成与词向量等长的一个向量,向量的奇偶位置数值计算如下:
位置向量与词向量相加形成最终输入的向量。
structure
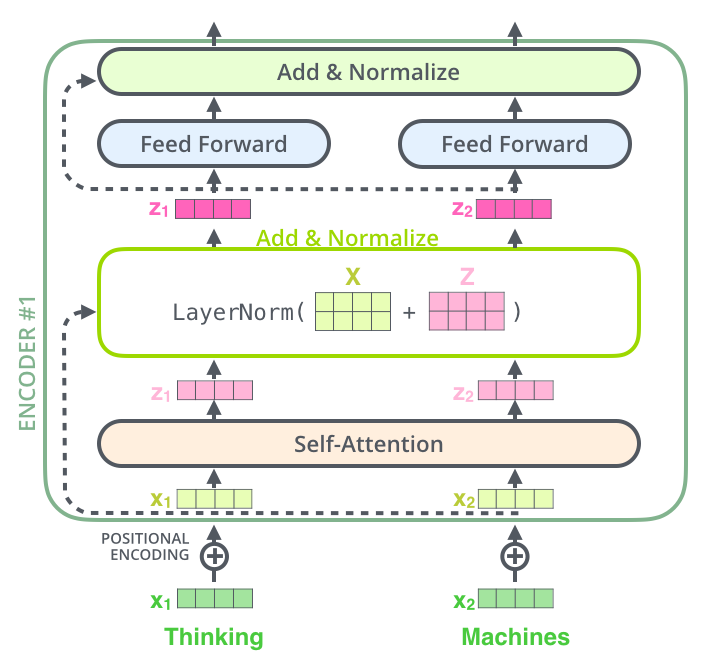
单个encoder的架构图如下,其中Normalize采用了layer-normalization.
decoder中服用了encode中的K, V.