nlp
09 seq2seq
YeeKal
•
•
"#nlp"
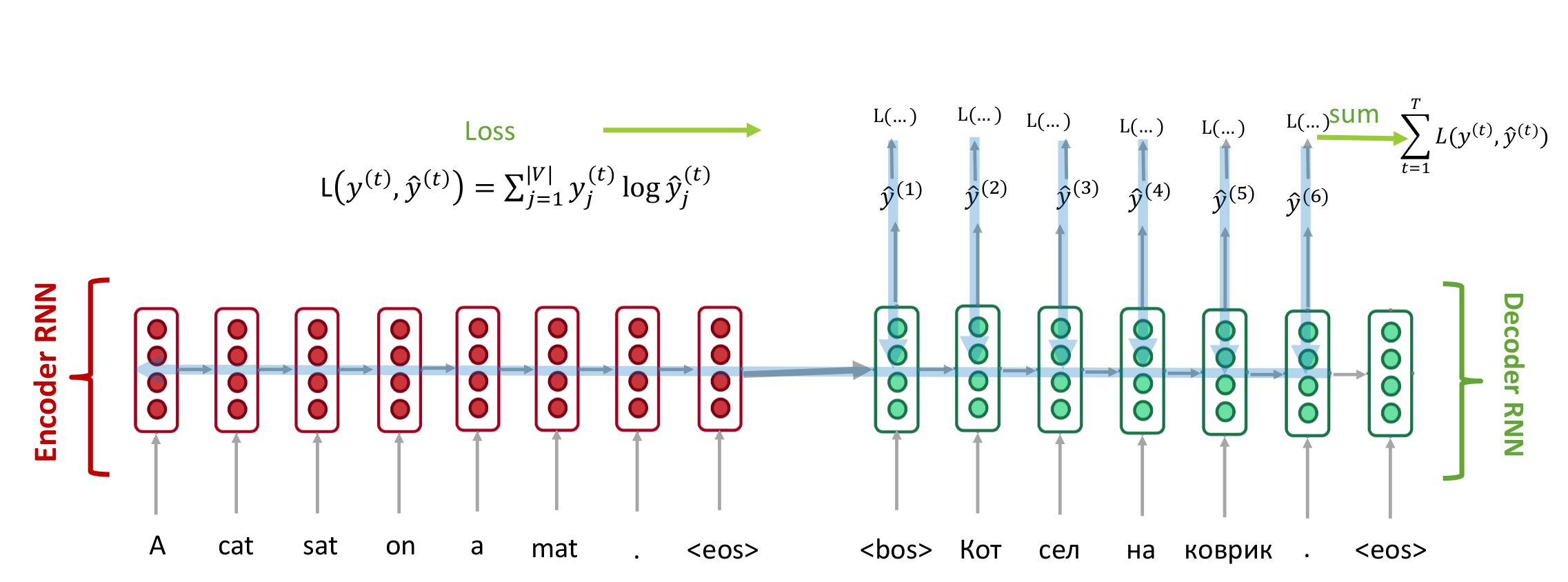
seq2seq
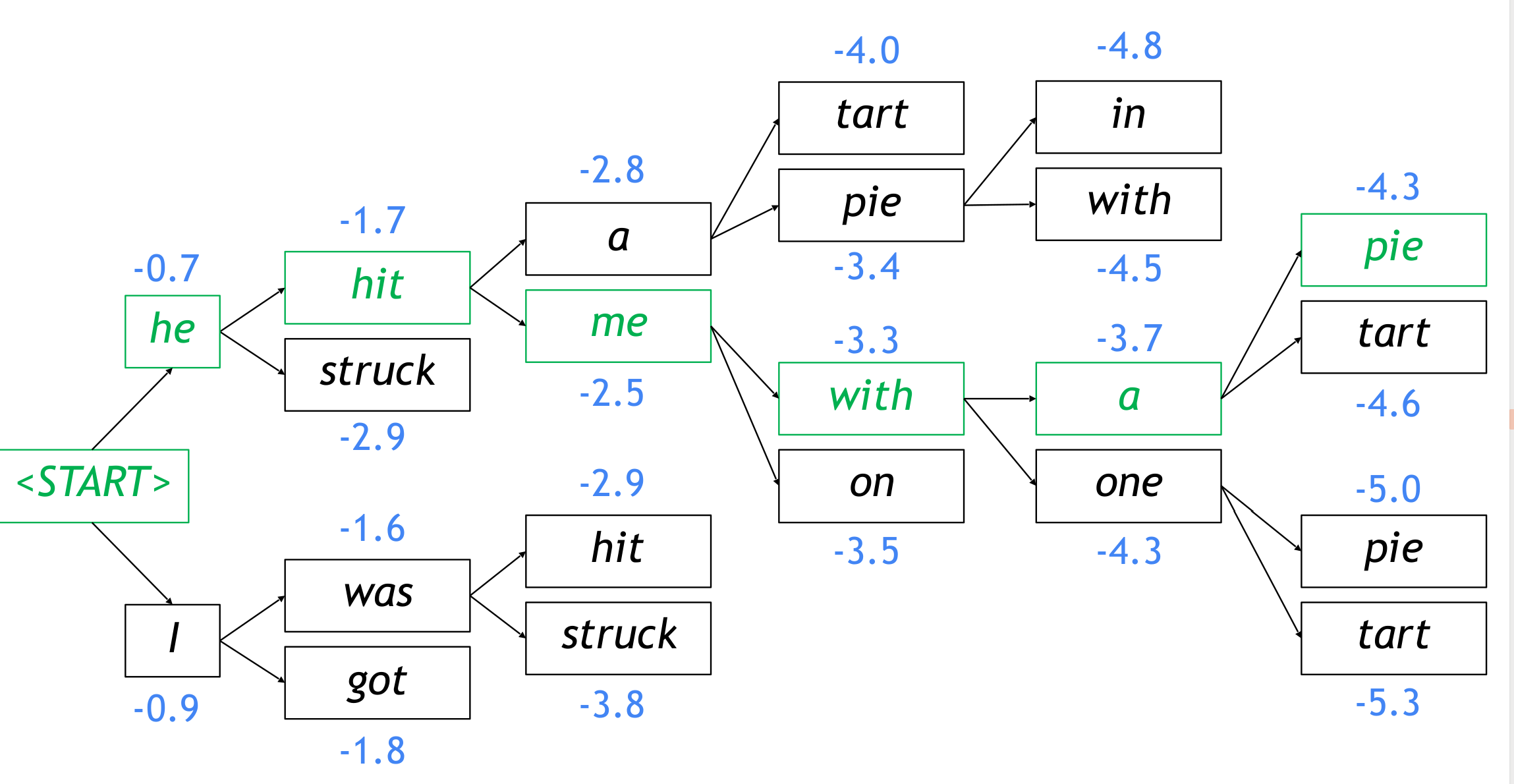
decoding:
1. greedy decoding: 取softmax最大值最为下一个输入
2. beam search:
attention
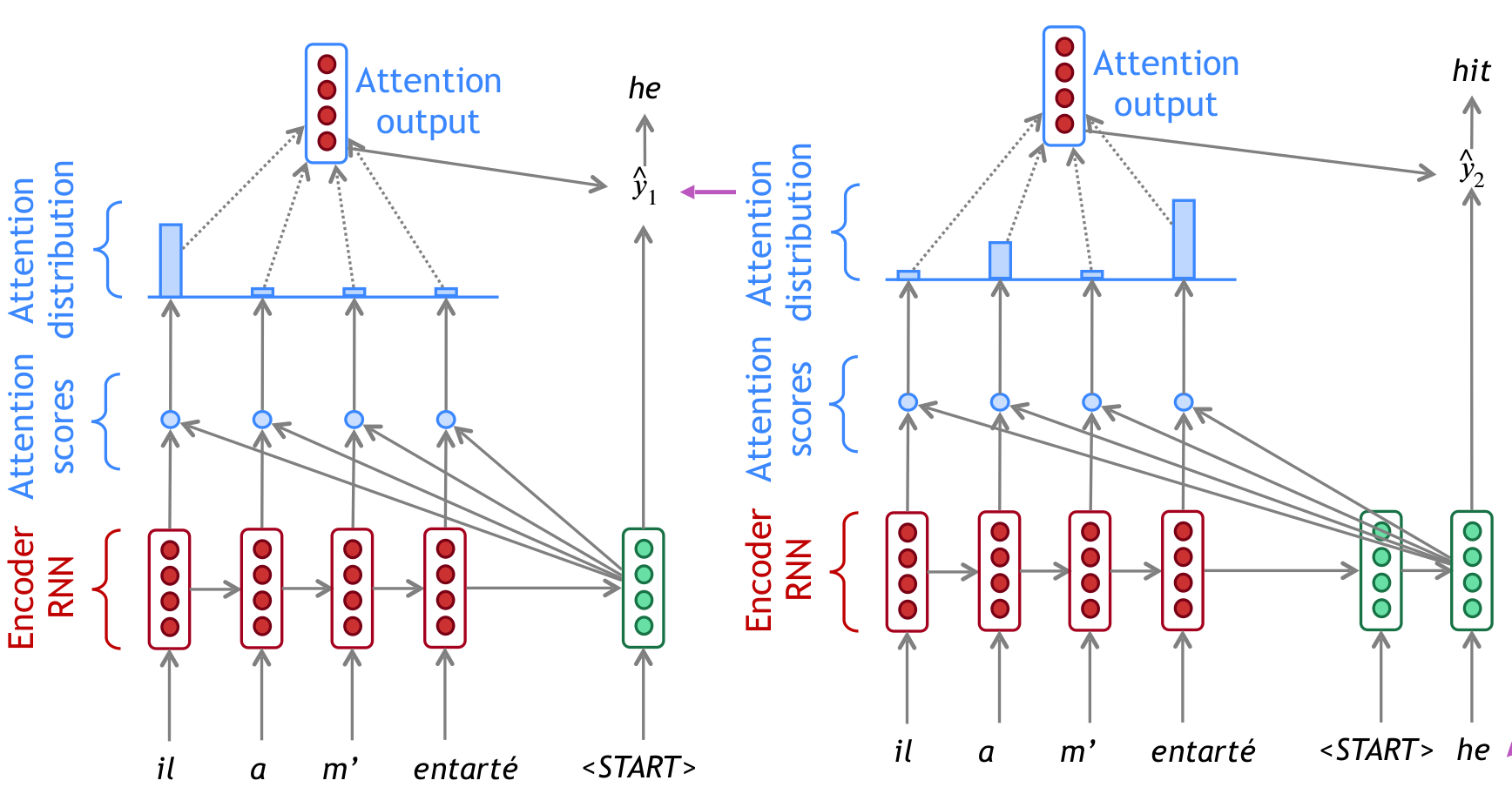
In equations: $$$$
any function can be applied to calculated attention scores: - Basic dot-product attention: $e_{i}=s^{T} h_{i} \in \mathbb{R}$ - Multiplicative attention: $e_{i}=s^{T} W h_{i} \in \mathbb{R}$, where $W \in \mathbb{R}^{d_{2} \times d_{1}}$ is a weight matrix - Additive attention: - $\quad W_{1} \in \mathbb{R}^{d_{3} \times d_{1}}, W_{2} \in \mathbb{R}^{d_{3} \times d_{2}}$ are weight matrices - $v \in \mathbb{R}^{d_{3}}$ is a weight vector. - $d_{3}($ the attention dimensionality) is a hyperparameter