05 language model
refer
- 了解N-Gram模型
- [speech and language processing]
language model: - count-based (statistical) - neural langiage models
n-gram
- one word sentence $W={w_1,w_2,\dots,w_n}$
- $w^n_1$ means the string $w_1,w_2,\dots,w_n$
With the chain rule of probability(链式规则), the probability of W:
In n-gram, approximate the history by just the last few words(markov assumption):
By maximum likelihood estimation(计算词频), 为了计算$w_{n-1}$下$w_{n}$的概率,把$w_{n-1}$和$w_{n}$出现在一起的次数除以$w_{n-1}$与所有词出现在一起的次数的总和,而事实上$w_{n-1}$与所有词出现在一起的次数就等于$w_{n-1}$出现的次数:
unigram, bigram, trigram
两大问题:
- 稀疏问题 Sparsity Problem。在我们之前的大量文本中,可能分子或分母的组合没有出现过,则其计数为零。并且随着n的增大,稀疏性更严重。
- 我们必须存储所有的n-gram对应的计数,随着n的增大,模型存储量也会增大。
deeper in n-gram
0. backoff:
"quietly on the" is not seen $\longrightarrow$ try "on the" "on the" is not seen $\longrightarrow$ try"the" "the" is not seen $\longrightarrow$ try unigram
1. weight: mix unigram, bigram, trigram
katz backoff: adjusting $\lambda$
2. smoothing
Laplace-smoothing(aka add-one smoothing): If 1 is too rude, add small $\delta$ to count for every $w_i\in V$
Kneser-Ney Smoothing:
evaluation
cross-entropy:
perplexity: perplexity $=2^{c r o s s-e n t r o p y}$
NNLM: neural networks language models
Fighting the Curse of Dimensionality with Distributed Representations: - associate with each word in the vocabulary a distributed word feature vector - express the joint probability function of word sequences in terms of the feature vectors of these words in the sequence - learn simultaneously the word feature vectors and the parameters of that probability function
learn model:
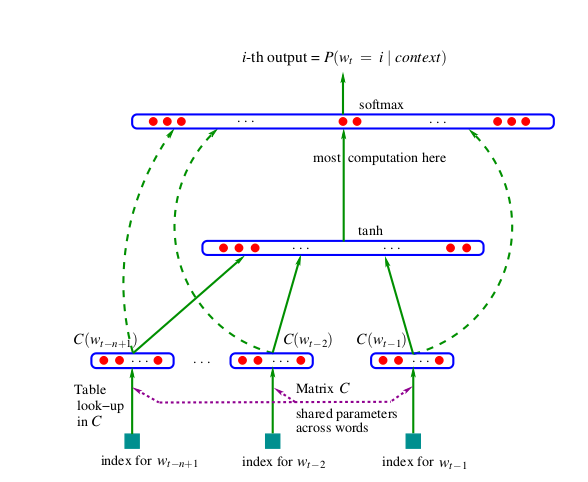
maximizes the object function:
the network structure: - input: $x=\left(C\left(w_{t-1}\right), C\left(w_{t-2}\right), \cdots, C\left(w_{t-n+1}\right)\right)$ - hidden layer: $y=b+W x+U \tanh (d+H x)$ - softmax output layer: $\hat{P}\left(w_{t} \mid w_{t-1}, \cdots w_{t-n+1}\right)=\frac{e^{y_{w_{t}}}}{\sum_{i} e^{y_{i}}}$ - update: $\theta \leftarrow \theta+\varepsilon \frac{\partial \log \hat{P}\left(w_{t} \mid w_{t-1}, \cdots w_{t-n+1}\right)}{\partial \theta}$
- rnn-2010
- lstm-rnn 2012
- bi-rnn
- cnn
- bert
lm
- 在纠错上的应用
- 语言模型,概念