03_word_embedding
ref
文本表示(Representation)
将文本转化为结构化,易于计算的数学形式。 - 独热编码(one-hot representation):无法表达词语之间的关系;过于稀疏,计算存储效率低 - 整数编码:无法表达词语之间的关系 - 分布式表示(distributed representation,Distributional semantics): 表示上下文 - 基于矩阵:GloVe - 基于聚类 - 基于神经网络: 词嵌入(word embedding)
The distributional hypothesis(分布假说): - 1954 by Harris: 上下文相似的词,其语义也相似 - 1957 by Firth:“You shall know a word by the company it keeps(词的语义由其上下文决定).”
Latent semantic analysis (LSA)
潜在语义分析/潜在语义索引(latent semantic indexing,LSI) - Latent Semantic Analysis: Distributional Semantics in NLP - A Beginner's Guide to Bag of Words & TF-IDF
major applications: - Document Similarity: Comparing the documents in low-dimensional spaces - Topic Modeling: Finding re-curring topics across documents - Text Synoymity: Finding relations between terms (Text Synoymity)
LSA inherently follows certain assumptions: 1. Meaning of Sentences or Documents is a sum of the meaning of all words occurring in it. Overall, the meaning of a certain word is an average across all the documents it occurs in. 2. LSA assumes that the semantic associations between words are present not explicitly, but only latently in the large sample of language.
Mathematical Perspective:
Given m documents and n-words in our vocabulary, we can construct an m × n matrix A in which each row represents a document and each column represents a word by Tf-IDF Vectorizer(Intuitively, a term has a large weight when it occurs frequently across the document but infrequently across the corpus.):
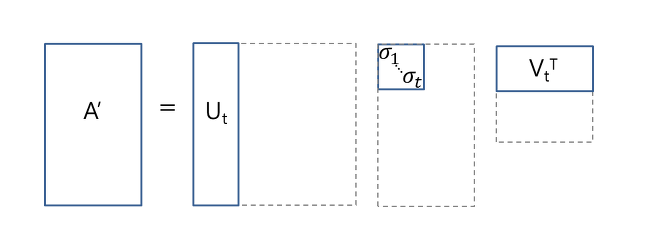
The matrix A is called document-term matrix. Then a Truncated Singular Value Decomposition is used to perform Dimensionality reduction.Truncated SVD reduces dimensionality by selecting only the t largest singular values, and only keeping the first t columns of U and V. In this case, t is a hyperparameter we can select and adjust to reflect the number of topics we want to find.
词嵌入(word embedding)
- 词嵌入: 把词映射为实数域向量的技术也叫词嵌入
- 词向量: 词嵌入将文本转化为一个低维向量,又叫做词向量
- 词向量不像one-hot那么长,便于存储,计算
- 词向量在向量空间的距离关系可以表示为词语的相似性
两种主流词嵌入算法: - word2vec - GloVe
word2vec
通过神经网络训练语言模型可以得到词向量,比如: - 2003 - Neural Network Language Model ,NNLM - Log-Bilinear Language Model, LBL - Recurrent Neural Network based Language Model,RNNLM - Collobert 和 Weston 在2008 年提出的 C&W 模型 - 2013 - Mikolov 等人提出了 CBOW( Continuous Bagof-Words)和 Skip-gram 模型
上面提到的神经网络语言模型,只是个在逻辑概念上的东西,而通过设计实现CBOW( Continuous Bagof-Words)和 Skip-gram 语言模型的工具正是word2vec。而CBOW和Skip-gram也被称为word2vec的两种训练模式。
word2vec model
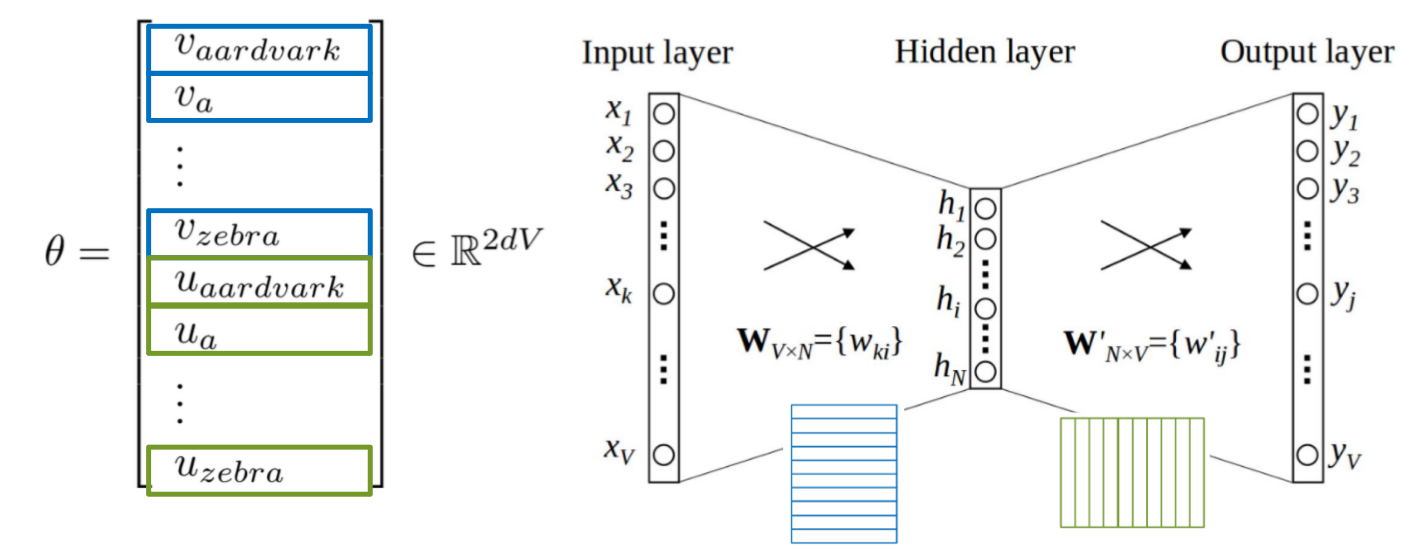
先假设每个词可以由高维向量$P(w_t)$表示,然后根据词间位置关系定义优化的概率模型,然后通过神经网络不断更新向量以最优化目标函数。
所有出现的句子都是正样本
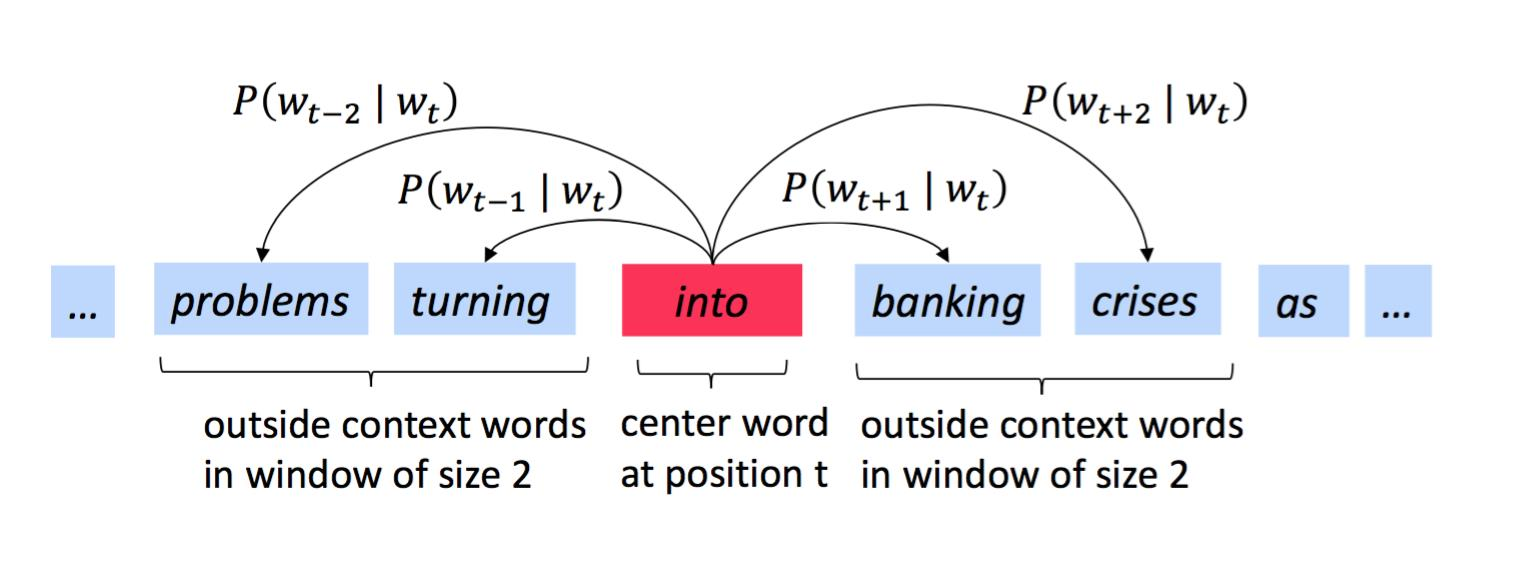
句子的概率为各个词的概率的联合概率,对于一条有T个单词的文本,以宽度为m的窗口来计算其概率:
$\theta$是需要优化的变量,即词向量中的向量值。根据最大似然估计,优化函数:
计算$P(w_{t+j}|w_j,\theta)$: - $v_w$ is a center word - $u_w$ is a context word - for a center word c and a context word o: - Dot product measures similarity of o and c - After taking exponent, normalize over entire vocabulary
softmax:
- SG(skip-gram): Predict context (”outside”) words (position independent) given center word
- CBOW(Continuous Bag of Word): Predict center word from (bag of) context words
GloVe
combine count-based and direct prediction methods
FastText
adding subword information
练习数据下载
中文维基百科的打包文件地址为链接: https://pan.baidu.com/s/1H-wuIve0d_fvczvy3EOKMQ 提取码: uqua
百度网盘加速下载地址:https://www.baiduwp.com/?m=index