ml
xgboost
YeeKal
•
•
"#ml"
目标函数
树模型的目标函数, 假设有$K$颗树, $\Omega(f_k)$为模型复杂度的惩罚因子,可以理解为正则项:
回归树不仅仅用作回归,回归,分类,排序都可以用回归树,关键再与怎么定义损失函数。
损失函数
树的提升过程:
通过梯度提升树. 在$t$时刻的目标函数:
以平方差损失举例:
可得:
去掉常数项(包括上一颗树的误差,对本棵树的构建就是常数):
(与gbdt对比,gbdt是根据随机梯度下降,更新方向为负梯度(一阶导);而xgboost根据二阶泰勒展开,类似于牛顿法,同时利用了一阶和二阶导)
复杂度
求解
根据二次方程求解
可得最小值:
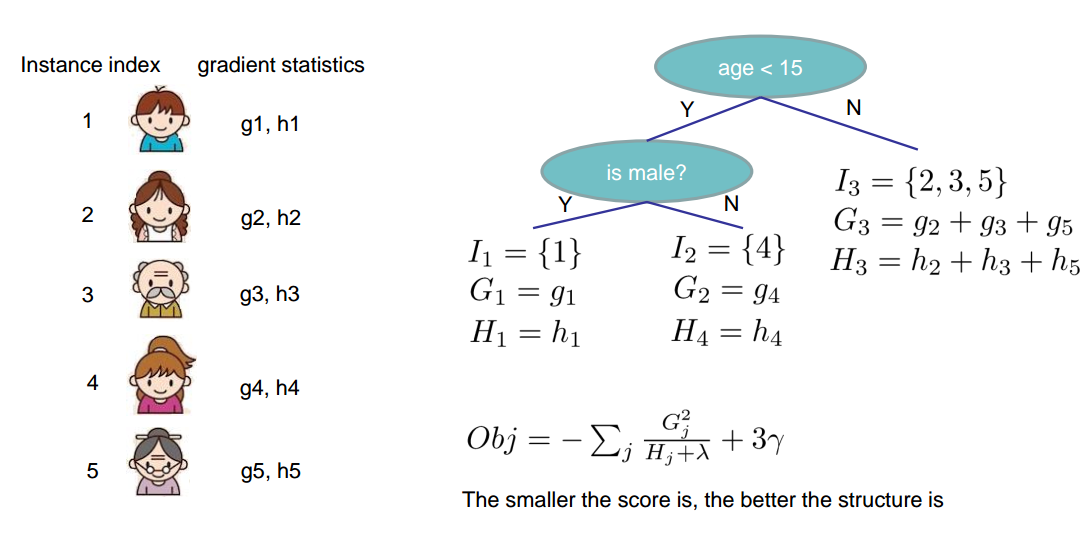
树模型的构建中最小化损失函数的理论公式并不是最终结果,因为还有叶子节点的分裂策略。比如在以MSE为损失函数的决策树中,负梯度的平均值是理论公式,而具体的损失还需要逐个特征扫描来确定最后的分裂点。因此上述公式也是第一步的理论公式,还需要下一步的分裂策略才能完成整个树的构建。损失函数和分裂策略也正是xgboost重点优化的地方。
分裂策略
分裂增益:
先对特征值排序,在进行线性扫描,可以高效率的找到最小值。
- 贪心法:遍历每一个特征值
- 近似法:根据特征的分布确定l个候选切分点,然后根据这些候选切分点把相应的样本放入对应的桶中,对每个桶的$G,H$ 进行累加。最后在候选切分点集合上贪心查找. 这样可以大大减少特征值选择的次数。
for f in features:
sort(f.values)
for fv in f.values: # linear scan
find min loss
find the best split
- 剪枝(prune)
- Pre-stopping
- Stop split if the best split have negative gain
- But maybe a split can benefit future splits..
- Post-Prunning
- Grow a tree to maximum depth, recursively prune all the leaf splits with negative gain
- Pre-stopping
- 学习率: 防止过拟合
并行方案
提升树的原理决定了无论什么算法都不能并行化得同时构建多颗树。而xgboost的并行也是在特征粒度上进行并行计算的。在选择哪个特征进行分裂时可以做并行;在具体某一特征选择特征值时也可以做并行。
缺失值处理
自动学习缺失值的分裂方向
xgb与gbdt的区别
- 损失函数:GBDT是一阶,XGB是二阶泰勒展开
- XGB的损失函数可以自定义,具体参考 objective 这个参数
- XGB的目标函数进行了优化,有正则项,减少过拟合,控制模型复杂度
- 预剪枝:预防过拟合
- GBDT:分裂到负损失,分裂停止
- XGB:一直分裂到指定的最大深度(max_depth),然后回过头剪枝。如某个点之后不再正值,去除这个分裂。优点是,当一个负损失(-2)后存在一个正损失(+10),(-2+10=8>0)求和为正,保留这个分裂。
- XGB有列抽样/column sample,借鉴随机森林,减少过拟合
- 缺失值处理:XGB内置缺失值处理规则,用户提供一个和其它样本不同的值,作为一个参数传进去,作为缺失值取值.XGB在不同节点遇到缺失值采取不同处理方法,并且学习未来遇到缺失值的情况。
- XGB内置交叉检验(CV),允许每轮boosting迭代中用交叉检验,以便获取最优 Boosting_n_round 迭代次数,可利用网格搜索grid search和交叉检验cross validation进行调参。 GBDT使用网格搜索。
- XGB运行速度快:data事先安排好以block形式存储,利于并行计算。在训练前,对数据排序,后面迭代中反复使用block结构。 关于并行,不是在tree粒度上的并行,并行在特征粒度上,对特征进行Importance计算排序,也是信息增益计算,找到最佳分割点。
- 灵活性:XGB可以深度定制每一个子分类器
- 易用性:XGB有各种语言封装
- 扩展性:XGB提供了分布式训练,支持Hadoop实现
- 共同优点:
- 当数据有噪音的时候,树Tree的算法抗噪能力更强
- 树容易对缺失值进行处理
- 树对分类变量Categorical feature更友好